全文阅读
用于和较长的上下文和文档进行问答。由于已经加入了gpt-3.5-turbo-16k模型,大部分时候已经不需要全文阅读功能就能能满足长文输入的需求,但使用这个功能后,仍可以继续超过16k的token长度限制。
有两种方式启用
- 如果粘贴一大段文字到输入框中提交,超过预设的限制(默认12000 token,可在
设置-最长输入中修改),会自动转成全文阅读模式 - 拖拽一个文件( txt, md, pdf, html, docx )到输入框后,也会开启全文阅读模式。然后可以对该文本中内容进行问答。
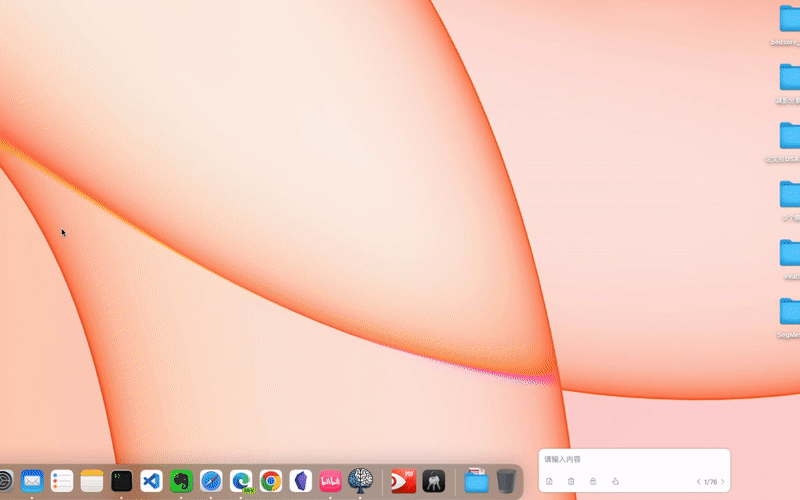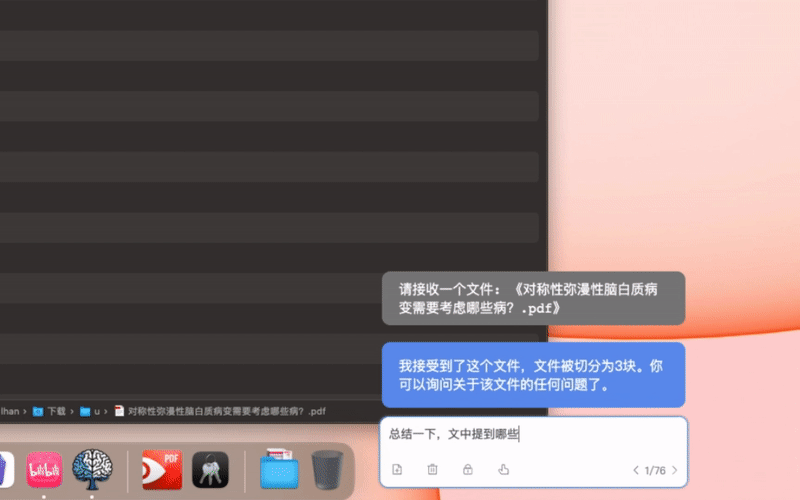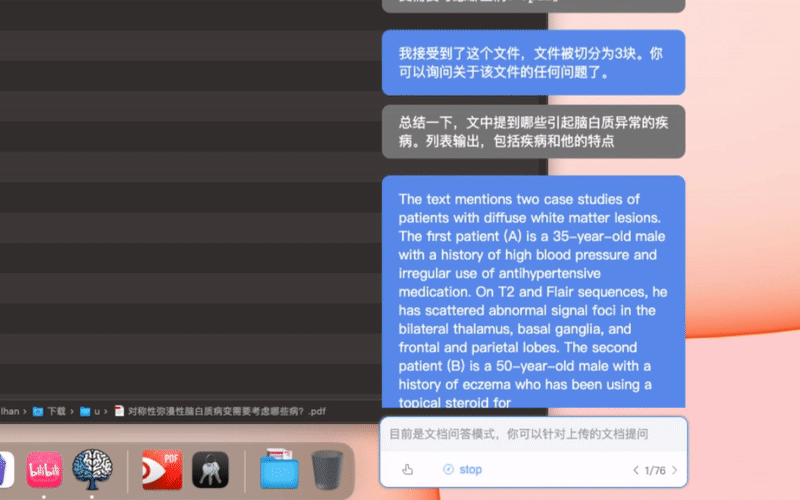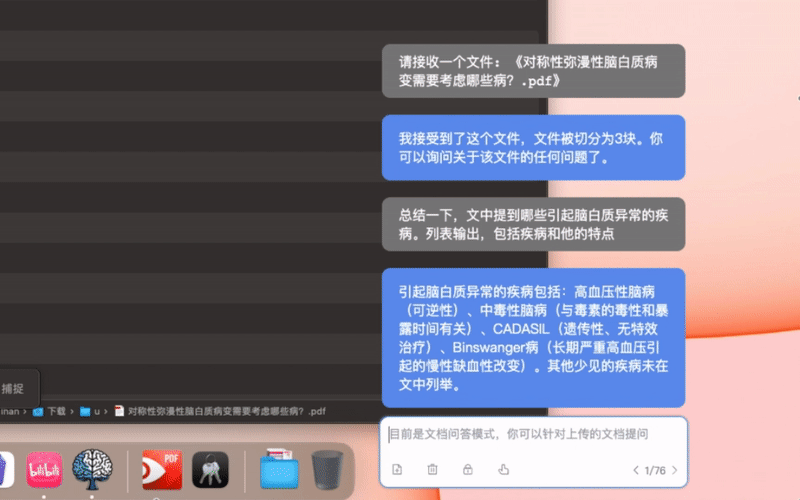
全文阅读的原理是分块阅读,就是带着问题,分块阅读所有文档片段并储存中间相关信息,最后汇总。这个方案不是把文档分块后用向量查询。向量查询有两个缺点,一个是如果你的问题在文中和上下文关系不大,可能查询不到。另一个是如果你的问题,需要整合全文各个部分信息后才能总结得出,也是无法完成的。全文阅读无论是细节的查询还是整体的查询都更好,但缺点是token消耗更大。比较适合需要分析准确度和完整度的场景。如果你需要分析的文本特别大,比如要针对几万几十万字的一本书进行问答,建议使用下面的“本地知识库”,把书本变成一个知识库,那个是使用向量查询的方案(embeding)。
下面是一些常用的全文阅读模式的提问方式,这些提问既有关注局部的也有关注全局的,基本上都能很好完成
- 总结文献:"总结一下这篇文献,关注和解决了一个什么问题,使用了什么方法,效果如何,有什么意义"
- 概括文件:"按顺序总结一下文件中提到的重要时间点和相应的安排,用markdwon表格输出,包括时间点,安排"
- 提取原文信息:"提取所有文中关于xxx相关的原文信息,使用json输出,字段'原文信息'"
- 续写(需要创作原文中没有的内容, 建议先总结再发挥): "简单总结一下文中提到的这个项目的基本情况,然后根据基本情况写一下文中的项目市场前景预测,经济效益与社会效益"
- 作为背景资料:"根据提供的文字作为背景资料,续写一下该项目项目创新点与技术优势。可以根据你的知识自由发挥。"